Inserting graphviz diagrams in a CVStrac wiki
CVStrac is an amazing productivity booster for any software development group. This simple tool, built around a SQLite database (indeed, by the author of SQLite) combines a bug-tracking database, a CVS browser and a wiki. The three components are fully cross-referenced and build off the strengths of each other. You can handle almost all aspects of the software development process in it, and since it is built on an open database with a radically simple schema, it is trivial to extend. I use CVStrac for Temboz to track bugs, but also to trace changes in the code base to requirements or to bugs, and last but not least, the wiki makes documentation a snap.
For historical reasons, my company uses TWiki for its wiki needs. We configured Apache with mod_rewrite so that the wiki links from CVStrac lead to the corresponding TWiki entry instead of the one in CVStrac itself, which is unused. TWiki is very messy (not surprising, as it is written in Perl), but it has a number of good features like excellent search (it even handles stemming) and a directed graph plug-in that makes it easy to design complex graphs using Bell Labs’ graphviz, without having to deal with the tedious pixel-pushing of GUI tools like Visio or OmniGraffle. The plug-in makes it easy to document UML or E-R graphs, document software dependencies, map process flows and the like.
CVStrac 2.0 introduced extensibility in the wiki syntax via external programs. This allowed me to implement similar functionality in the CVStrac native wiki. To use it, you need to:
- Download the Python script dot.py and install it somewhere in your path. The sole dependency is graphviz itself, as well as either pysqlite2 or the built-in version bundled with Python 2.5
- create a custom wiki markup in the CVStrac setup, of type “Program Block”, with the formatter command-line:
path/dot.py –db CVStrac_database_file –name ‘%m’- Insert the graphs using standard dot syntax, bracketed between CVStrac {dot} and {enddot} tags.
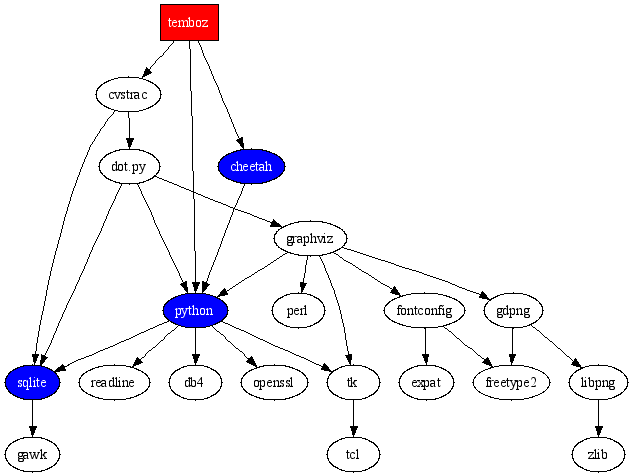
{dot}
digraph sw_dependencies {
style=bold;
dpi=72;
temboz [fontcolor=white,style=filled,shape=box,fillcolor=red];
python [fontcolor=white,style=filled,fillcolor=blue];
cheetah [fontcolor=white,style=filled,fillcolor=blue];
sqlite [fontcolor=white,style=filled,fillcolor=blue];
temboz -> cheetah -> python;
temboz -> python -> sqlite -> gawk;
temboz -> cvstrac -> sqlite;
python -> readline;
python -> db4;
python -> openssl;
python -> tk -> tcl;
cvstrac -> "dot.py" -> graphviz -> tk;
"dot.py" -> python;
"dot.py" -> sqlite;
graphviz -> gdpng;
graphviz -> fontconfig -> freetype2;
fontconfig -> expat;
graphviz -> perl;
graphviz -> python;
gdpng -> libpng -> zlib;
gdpng -> freetype2;
}
{enddot}
Another useful plug-in for CVStrac I wrote is one that highlights source code in the CVS browser using the Pygments library. Simply download pygmentize.py, install it Setup/Diff & Filter Programs/File Filter, using the string path_to/pygmentize.py %F. Here is an example of Pygment applied to pygmentize.py itself:
#!/usr/bin/env python
# $Log: pygmentize.py,v $
# Revision 1.3 2007/07/04 19:54:26 majid
# cope with Unicode characters in source
#
# Revision 1.2 2006/12/23 03:51:03 majid
# import pygments.lexers and pygments.formatters explicitly due to Pygments 0.6
#
# Revision 1.1 2006/12/05 20:19:57 majid
# Initial revision
#
"""
CVStrac plugin to Pygmentize source code
"""
import sys, pygments, pygments.lexers, pygments.formatters
def main():
assert len(sys.argv) == 2
block = sys.stdin.read()
try:
lexer = pygments.lexers.get_lexer_for_filename(sys.argv[1])
out = pygments.highlight
block = pygments.highlight(
block, lexer, pygments.formatters.HtmlFormatter(
style='colorful', linenos=True, full=True))
except ValueError:
pass
print unicode(block).encode('ascii', 'xmlcharrefreplace')
if __name__ == '__main__':
main()
