RSS/Atom and information overload
I have been running Temboz, my home-made RSS/Atom aggregator, for half a year now, and it is interesting to take stock. I ran a report on the database to count how many items per day I read, how many are filtered out automatically, and how many I flagged as interesting.
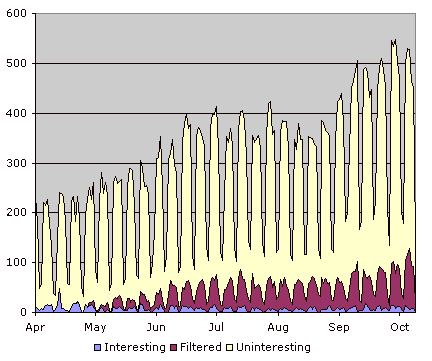
The most obvious thing is the steady increase in the number of articles per day, while the number of articles I flag as interesting remains mostly constant (perhaps a sign of greater selectivity). The increase is primarily due to an increase in the number of feeds I subscribe to — as the ergonomics of the feed reader improved (at least from my perspective), I can read more feeds. The addition of filtering also allows me to read via RSS sources of information I used to check daily, such as the Photo.net forums. As time goes, I find I seldom regularly visit web sites on a daily basis any more, not even the New York Times (granted, the steadily deteriorating quality of their journalism might have something to do with that).
My filtering scheme is manual and rules-based. I am a bit leery of implementing something like Bayesian filtering, as articles I flag as “uninteresting” are not necessarily articles I would like to be filtered away – some are duplicates, some are worth a chuckle but not much more. The risk with the “Daily Me” is to lock oneself into a routine and self-reinforcing echo chamber, so I try and keep a balanced diet of information. Some subjects I am completely uninterested in, however, for instance one of my rules filters out anything sports-related from The Guardian.
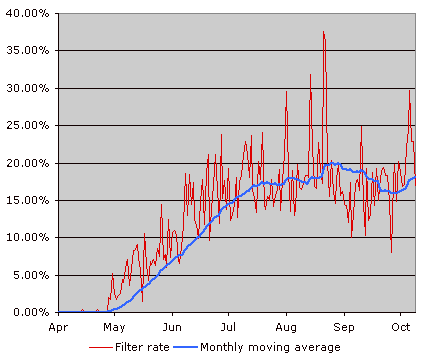
As I enrich my library of filtering rules, the proportion of articles filtered is increasing steadily (the recent dip in September was caused by a flurry of feed subscriptions). A 20% time savings is nothing to sniff at. Fatigue plays a role — I dislike phones and finally got fed up with the plethora of cell phone reviews this week and filtered out all articles dealing with phones altogether.
One big win would be an algorithm that could reliably detect and group together articles that are on the same topic, the way Google News does (Google News has the potential to be the ultimate RSS/Atom aggregator). I experimented with a scheme to look for duplicated URLs inside the articles, but this didn’t work very well. Some form of statistical natural language processing would be needed, but that is more work than I am prepared to put in right now.