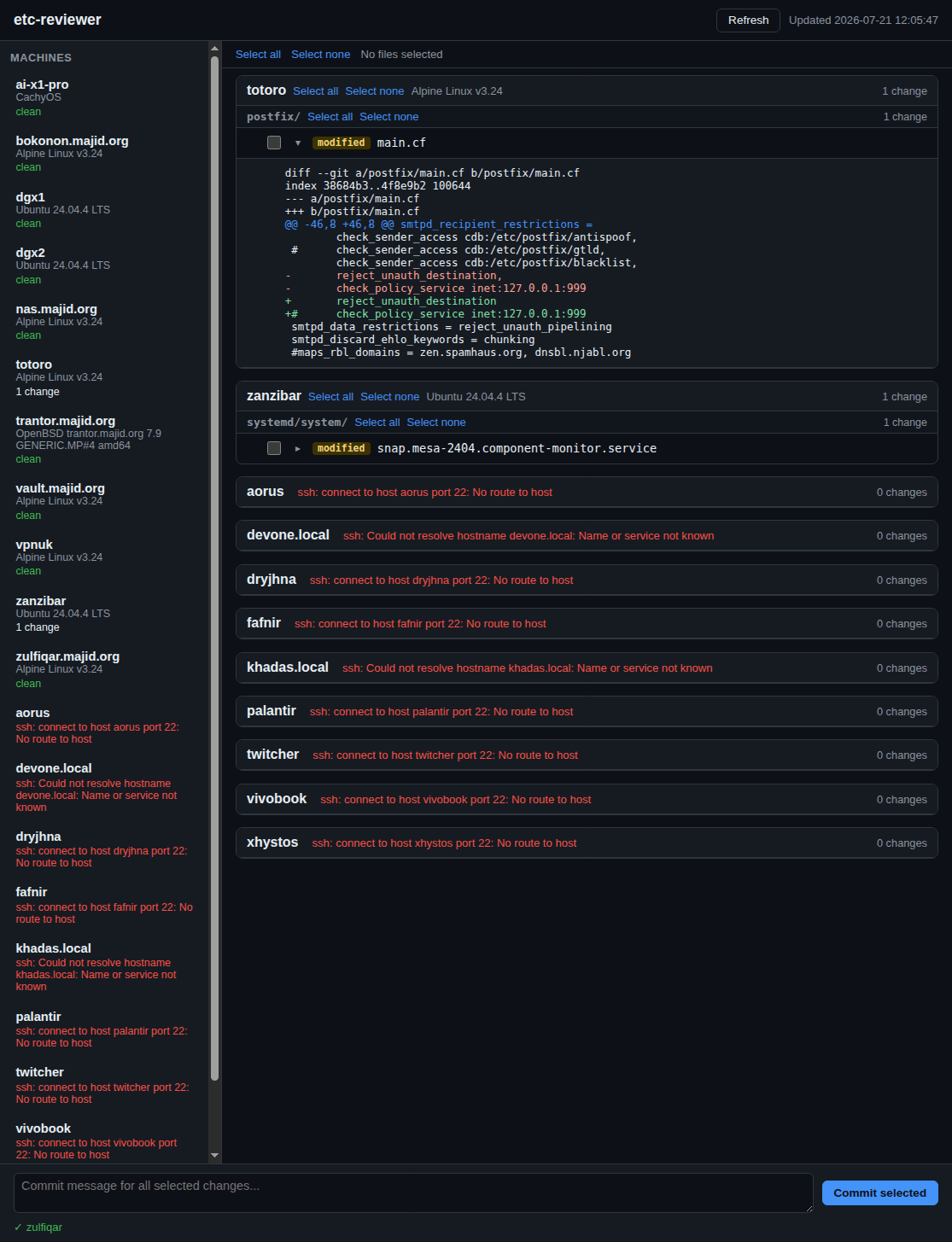
One of the downsides of self-hosting critical applications like email on your
homelab is that if you lose connectivity, especially when you are travelling,
you are out of luck. It’s happened to me twice. The first time I had to ask a
colleague (Hi Jason!) to go get my spare keys from the building super and
reboot my home server. In the other instance, I walked my wife over the phone
through the steps of rebooting our OpenBSD home router that runs on a somewhat
dubious computer sourced from AliExpress with an Intel N100. I actually
ordered an industrial-grade Asus NUC 13 Rugged N50 to replace it, but in
a variant of the Heisenberg effect, the original machine started working
flawlessly, go figure.
On some of my HP machines (Z workstations and EliteDesk 8xx Mini), the
firmware includes Intel AMT/IME spyware management firmware. You can
install the MeshCommander software to get a poor man’s version of the
IPMI remote management facility included in most servers. IPMI usually
includes remote KVM, i.e. being able to control the computer over the network
as if you were directly in front of its keyboard, mouse and monitor. KVM
stands for Keyboard, Video and Mouse, although most KVM systems also give you
the ability to insert a virtual USB drive to boot into diagnostics or a rescue
drive. This allows access to the BIOS and other things you can’t do from the
OS itself, or recover if the OS itself has crashed.
To resolve this vulnerability, I have been equipping the majority of my key
machines that don’t have Intel AMT with physical IP KVM devices. These used to
be very expensive and required having some cursed version of the Java plugin
installed in your browser, but recently the Pi-KVM project has opened up
the market and there are now a host of relatively inexpensive (in the $100
range) devices available like the JetKVM and GL.iNet’s Comet line of
IP KVMs.
GL.iNet is known for its well-regarded line of travel routers like the tiny
but mighty Mango, but has been expanding into IoT and now IP KVMs. That line
is now quite extensive, with:
- The basic Comet GL-RM1.
- A variant with PoE, the GL-RM1PE which also supports USB-C PD for power.
- A pro variant, the GL-RM10 (I haven’t tried it).
- More interestingly, a 5G cellular equipped model, the GL-RM10C.
Like their travel routers, the KVMs have an open operating system based on
Linux with SSH and root access, and excellent support for VPN protocols
actually invented in this millennium, i.e. WireGuard rather than hoary L2TP,
PPTP, IKE/IPsec or OpenVPN.
I have a basic Comet, two PoE powered ones and the 5G cellular one attached to
the router.
Due to the exhaustion of available IPv4 address pools, almost all cellular
carriers today use some form of Carrier-grade NAT (CGNAT), which means you do
not have a permanent IP address for your mobile device. Some cellular carriers
will offer plans with static IP addresses, but they are extremely expensive
including the per-kilobyte charges because this is a niche market, primarily
enterprises wanting remote monitoring and access to satellite offices.
GL.iNet offers a cloud service for remote access and also supports Tailscale
and ZeroTier. Either of these would obviate the need for an exotic data plan
SIM. I don’t trust the cloud, however, and find Tailscale too invasive, so I
opted instead to set up WireGuard between the GL-RM10C and a cloud server,
with routes forcing it to use the 5G wwan0 interface instead of Ethernet for
the tunnel.
The /etc/wireguard/wg0.conf config on the server is:
[Interface]
Address = 192.168.2.1/24, fddd::ffff/64
ListenPort = 51820
PrivateKey = <redacted>
PostUp = iptables -A FORWARD -i %i -j ACCEPT; iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE;iptables -A FORWARD -o %i -j ACCEPT; ip6tables -A FORWARD -i %i -j ACCEPT; ip6tables -t nat -A POSTROUTING -o eth0 -j MASQUERADE;ip6tables -A FORWARD -o %i -j ACCEPT
PostDown = iptables -D FORWARD -i %i -j ACCEPT; iptables -t nat -D POSTROUTING -o eth0 -j MASQUERADE;iptables -D FORWARD -o %i -j ACCEPT; ip6tables -D FORWARD -i %i -j ACCEPT; ip6tables -t nat -D POSTROUTING -o eth0 -j MASQUERADE;ip6tables -D FORWARD -o %i -j ACCEPT
[Peer]
PublicKey = <redacted>
AllowedIPs = 192.168.2.2/32, fddd::1/128
on the GL-KVM, it is:
[Interface]
Address = 192.168.2.2/24, fddd::1/64
#ListenPort = 51820
PrivateKey = <redacted>
[Peer]
PublicKey = <redacted>
AllowedIPs = 192.168.2.0/24
Endpoint = <redacted>:51820
PersistentKeepalive = 30
Add opening UDP port 51820 on the firewall, and on the KVM a /etc/init.d
startup script to call route add <ip of server> wwan0 and
wg-quick up wg0 at boot time, that establishes the tunnel. Since the IPs on
either end are not routable, I also have HAProxy running in TCP mode on the
server to allow access from the Internet:
global
log /dev/log local0
log /dev/log local1 notice
daemon
user nobody
group nobody
defaults
mode tcp
log global
option tcplog
timeout connect 5s
timeout client 1m
timeout server 1m
frontend https_in
bind <redacted>:443
default_backend wg_https_out
backend wg_https_out
mode tcp
server wg0_peer 192.168.2.2:443 check
I have a £5/month SIM card and plan installed, with a 5GB quota. I only start
HAProxy when I actually need it so I don’t waste any of it on script kiddies
trying to break in.
Finally, the GLKVM OS seems to overwrite WireGuard configs and /etc/init.d
(but fortunately not the /root/.ssh/authorized_keys) so to bring up WG on the
GLKVM, I run this script out of an hourly crontab:
#!/bin/sh
PATH=/usr/local/bin:${PATH}:/usr/sbin
LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/lib:/usr/local/postgresql/lib
export PATH
export LD_LIBRARY_PATH
set -e
cd $HOME
printf '\033[1;32m%s\033[0m\n' 'Recreating wg0.conf'
ssh root@glkvm "cat > /etc/wireguard/wg0.conf" <<EOF
[Interface]
Address = 192.168.2.2/24, fddd::1/64
#ListenPort = 51820
PrivateKey = <redacted, private key of the GLKVM>
[Peer]
PublicKey = <redacted, public key of the WG server>
AllowedIPs = 192.168.2.0/24
Endpoint = <redacted, public IP of the WG server>:51820
PersistentKeepalive = 30
EOF
ssh root@glkvm "chmod 600 /etc/wireguard/wg0.conf"
printf '\033[1;32m%s\033[0m\n' 'Waiting for wwan0 to come up'
iface=wwan0
ssh root@glkvm <<EOF
while :; do
ip link show dev "$iface" >/dev/null 2>&1 || {
sleep 1
echo waiting for $iface to be plumbed
continue
}
ip link show dev "$iface" 2>/dev/null | grep -q 'state UP' || {
sleep 1
echo waiting for $iface to come up
continue
}
break
done
EOF
printf '\033[1;32m%s\033[0m\n' 'Routes'
ssh root@glkvm "route -n"
printf '\033[1;32m%s\033[0m\n' 'Adding cellular route to vpnuk'
ssh root@glkvm "route add <redacted, public IP of the WG server> wwan0" || true
ssh root@glkvm "route -n|grep wwan0"
printf '\033[1;32m%s\033[0m\n' 'Starting wg'
ssh root@glkvm "wg-quick up wg0" || true
sleep 2
printf '\033[1;32m%s\033[0m\n' 'wg status'
ssh root@glkvm "wg"
The user interface is largely the same across the entire GL.iNet KVM product
line, is excellent, uses native Web technologies and WebRTC to provide the
remote video, so no janky VNC plugins or Java required. The video is crisp, as
can be expected from a purely digital signal path, and I haven’t noticed
compression artifacts, even when running over cellular.
It does have the same problem as almost all IoT devices with a Web UI, of not
being able to self-provision a TLS certificate. I modified my monthly Let’s
Encrypt certificate rotation script to copy the keys and certificates to
/etc/kvmd/user/ssl/server.{key,crt} where the firmware expects them to
be. There is an IETF effort to fix this once and for all, but it is still
very much work-in-progress and probably still too complex for the average
consumer to deal with.
It’s also worth noting the 5G in the Comet 5G is RedCap (reduced capability),
which is a cheaper and more power-efficient version of 5G that is capped at
around 100Mbps instead of the gigabit speeds full-fat 5G offers. This is
unlikely to be an issue for this class of devices, as people are not buying
them to play Doom remotely.
What you don’t get with the Comets is the ability to remotely power-cycle the
machine you get with IPMI or AMT. They have an accessory for computers with
ATX motherboards, but I haven’t had one in ages, and a Rube Goldberg-like
contraption poetically named Fingerbot that physically pushes the power
button. JetKVM does have an accessory that interposes between computers with a
barrel DC connector and their power brick, to allow turning them on and
off. Let’s hope GL.iNet is inspired to make their own, and also a USB-C one
while they are at it. In the meantime, I plan on using a smart-home type
Wi-Fi-controlled power switch running Tasmota to do forced power cycles.
I also have a JetKVM. It’s a cute little device, very compact (but
surprisingly heavy), and I am planning to add it to my portable
computer-maintenance toolkit rather than keeping it stationary like my Comets.