2013-03-14: Google’s announcement that their Reader service will be discontinued has spurred interest in Temboz. This software is not dead, in fact I use it daily, but have not made an official release in a long time. You should use the version from Github instead. There are currently a number of bugs which can lead to Temboz locking up and requiring a restart. I am planning on completing my long overdue overhaul before Google’s July deadline.
Contents
Introduction
Temboz is a RSS aggregator. It is inspired by FeedOnFeeds (web-based personal aggregator), Google News (two column layout) and TiVo (thumbs up and down). I have been using FeedOnFeeds for some time now, but that software seems to have stopped evolving, and I had a number of optimizations to the user experience I wanted to make.
Features
Already implemented:
- Multithreaded, download feeds in parallel.
- Built-in web server.
- Two-column user interface for better readability and information density. Automatic reflow using CSS.
- Ratings system for articles
- Real-time hunter-gatherer user interface: items flagged with a “Thumbs down” disappear immediately off the screen (using Dynamic HTML), making room for new articles. No laborious flagging of items as in FeedOnFeeds.
- Filtering entries (using Python syntax, e.g. ‘Salon’ in feed_title and title == “King Kaufman’s Sports Daily”, or simply by selecting keywords/phrases and hitting “Thumbs down”).
- Ability to generate a RSS feeds from “Thumbs Up” articles, which is why Temboz would be a true aggregator, not just a reader.
- Ad filtering
- Automatic garbage collection: every day between 3AM and 4AM, uninteresting articles (by default those older than 7 days) are purged of their contents (but not metadata such as titles, permalinks or timestamps) to keep the database size manageable. After 6 months (by default), they are deleted altogether
- Automatic database backups daily (immediately after garbage collection)
On the to do list:
- Write better documentation
- Handle permanent HTTP redirects for feed XML URLs
- Automatic pacing of feed polling intervals using the average and standard deviation of observed feed item inter-arrival times, to reduce bandwidth usage and load for both client and server. Most feeds should be polled on a daily rather than hourly interval (e.g. my own, since I update once a week on average), but the mechanisms for a feed to indicate its polling rate preferences are quite inconsistent from one flavor of RSS/Atom to another.
- “Survivor mode” – vote feeds that no longer perform off the aggregator based on relevance statistics.
- Ability to cluster together articles (I tried a heuristic of looking for common URLs they are all pointing to, but this didn’t work well in practice).
- Portability to Windows, distribution as a standalone package.
History
I have been using it successfully for well over a year. It still has rough edges, with some administration functions only doable using the SQLite command-line utility. Here is a screen shot showing the reader user interface. The article highlighted in yellow was given a “Thumbs Up”. You can also see the user interface at work in a view of the last 50 articles I flagged as “thumbs up” among the feeds I read.
Screen shots
Click on a screen shot thumbnail for a full-sized version
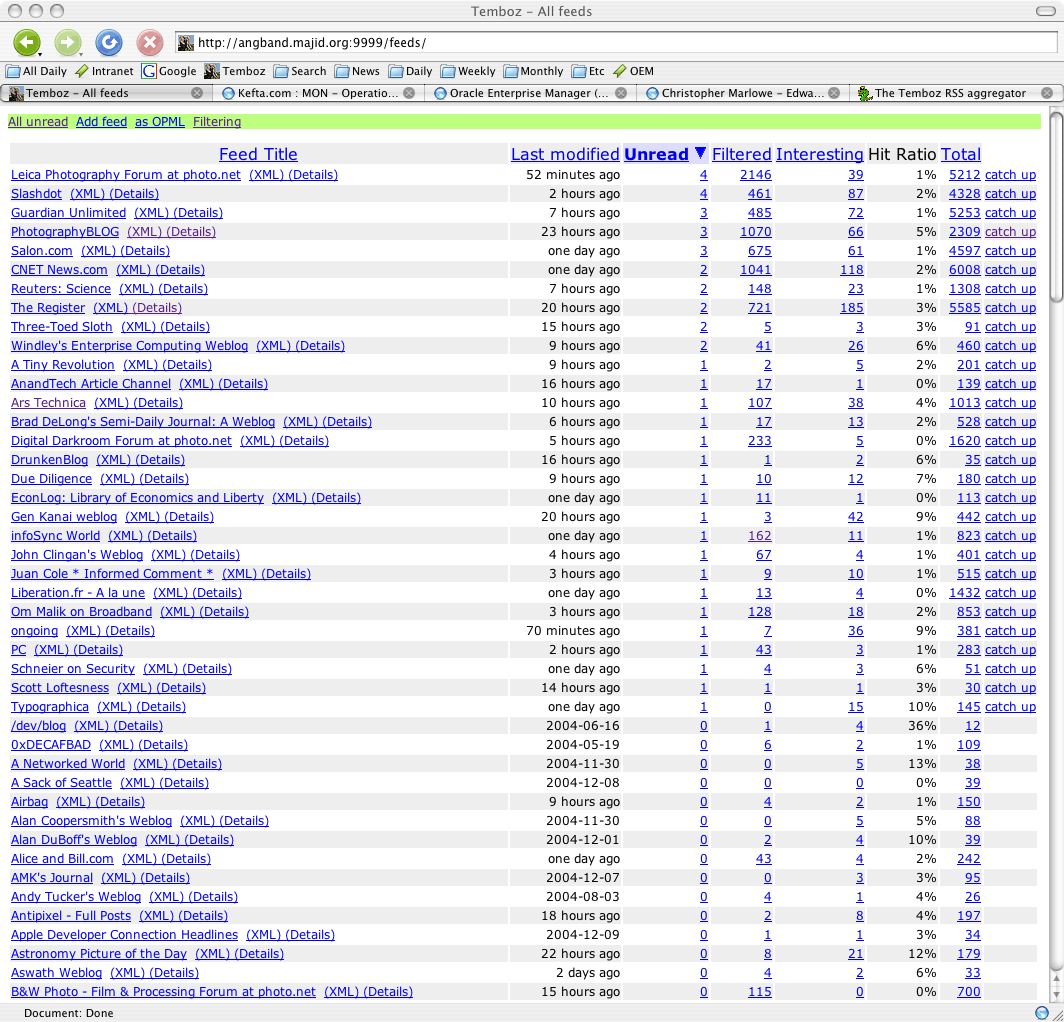
The first screen shot shows the article reading interface, using a two-column layout. Clicking on the “Thumbs down” icon makes the article disappear, bringing a new one in its place (if available). Clicking on the “Thumbs up” icon highlights it in yello and flags it as interesting in the database.
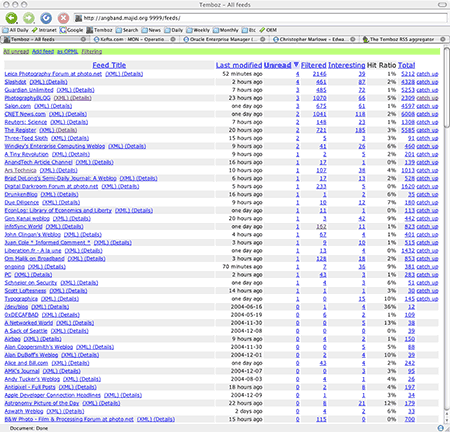
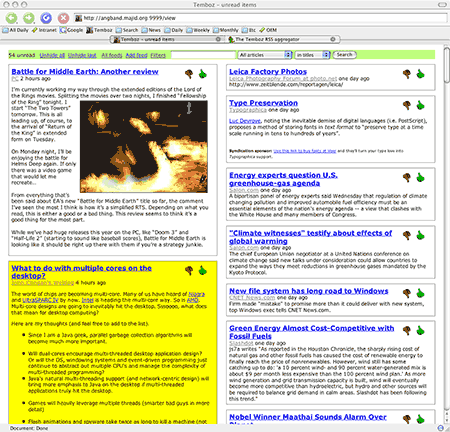 The feed summary page shows statistics on feeds, starting with feeds with unread articles, then by alphabetical order. Feeds can be sorted based on other metrics. You have the option of “catching up” with a feed (marking all the articles as read). Feeds with errors are highlighted in red (not shown).
The feed summary page shows statistics on feeds, starting with feeds with unread articles, then by alphabetical order. Feeds can be sorted based on other metrics. You have the option of “catching up” with a feed (marking all the articles as read). Feeds with errors are highlighted in red (not shown).
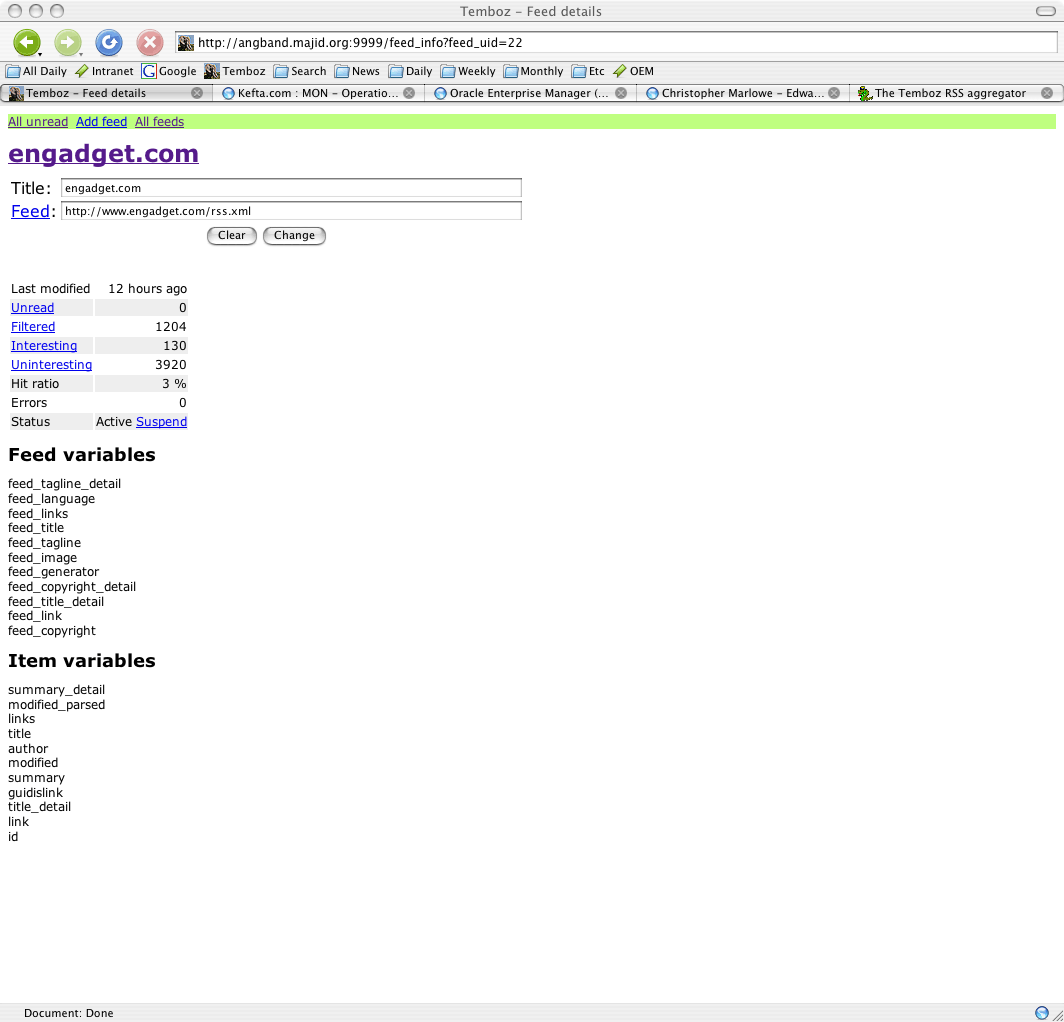
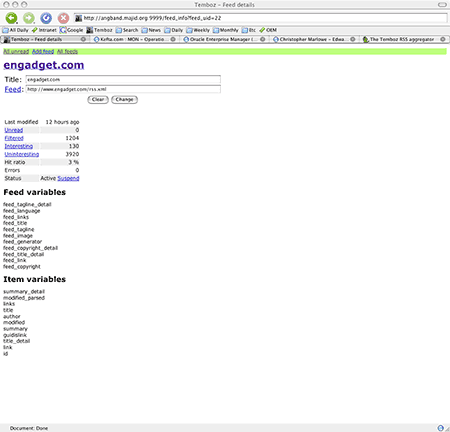
 Clicking on the “details” link for a feed brings this page, which allows you to change title or feed URL, and shows the RSS or Atom fields accessible for filtering.
Clicking on the “details” link for a feed brings this page, which allows you to change title or feed URL, and shows the RSS or Atom fields accessible for filtering.
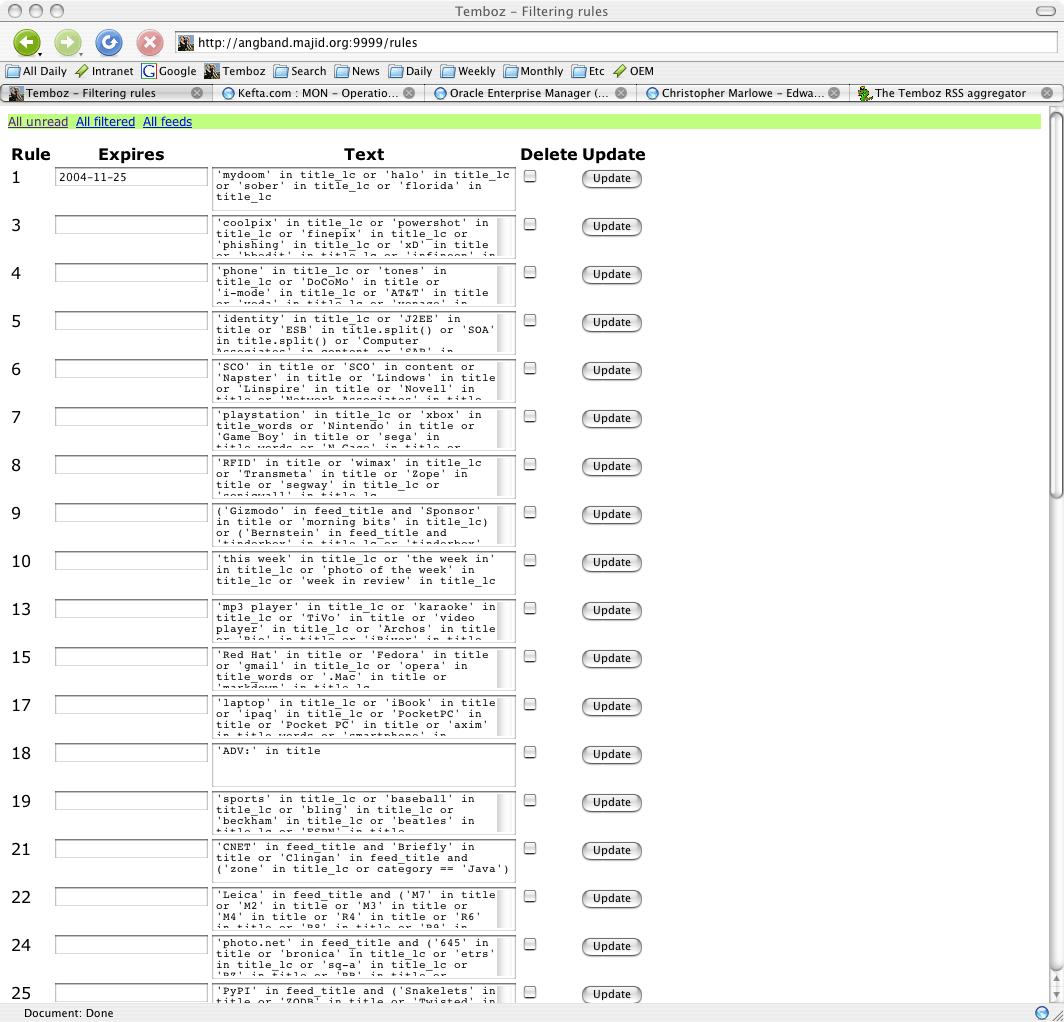
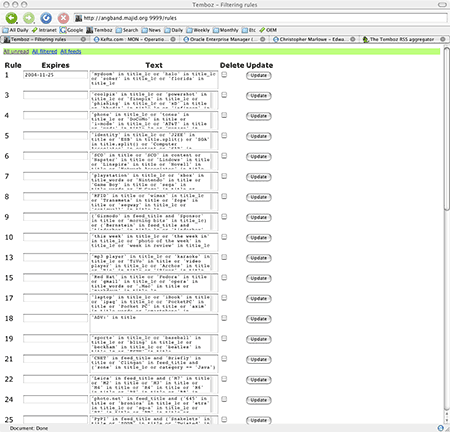
 Feeds can be filtered using Python expressions.
Feeds can be filtered using Python expressions.
Known bugs
You can check outstanding bug reports, change requests and more at the public CVStrac site.
Credits
Temboz is written in Python, and leverages Mark Pilgrim’s Ultra-liberal feed parser, SQLite 2.x, Cheetah.
Download
You can download the current version: temboz-0.8.tar.gz I welcome any feedback you may have, specially as concerns improving installation.
The CVS version is far ahead of 0.8 in features. I have not yet had the time to test and document the migration procedure from 0.8 to 1.0, but if you are a new Temboz user I strongly advise you to get a nightly CVS snapshot instead (they are what I run on my own server): temboz-CVS.tar.gz or temboz-CVS.zip.
Updates
For news on Temboz, please subscribe to the RSS feed.
Temboz has a CVStrac where you can submit bug reports or change requests, and a Wiki, where all future documentation will ultimately reside.
Post scriptum
The name “Temboz” is a reference to Malima Temboz, “The mountain that walks”, an elephant whose tormented spirit is the object of Mike Resnick’s excellent SF novel, Ivory.